 PDF(1308 KB)
PDF(1308 KB)

Multi⁃tool coordinated call with reasoning to annotation and coding prompt paradigm based on large language model
ZhiYing JIANG, ZhenYu HUANG, ChenWei SONG, ZeYu ZHANG, ZhongHe HAN, WeiWei GU, QiHang GONG, SiYe LIU, Yan ZHAO
Journal of Beijing University of Chemical Technology ›› 2025, Vol. 52 ›› Issue (3) : 105-113.
PDF(1308 KB)
PDF(1308 KB)
Multi⁃tool coordinated call with reasoning to annotation and coding prompt paradigm based on large language model
Because large language models show good understanding and generation capabilities, various industries have begun to study automated intelligent assistants based on these models, calling upon tools to help people solve complex problems. Large language models are prone to hallucination problems when generating responses due to the closed and complex data in the training phase. When facing complex problem planning, large language models often find it difficult to accurately generate function names and parameters when calling multiple different tools, and cannot coordinate the invocation of multiple tools to find answers. To improve the model’s tool call accuracy when planning tasks for complex problems, this paper proposes a prompt method that employs a chain-of-thought approach, Reasoning to Annotation and Coding (ReACo). This method fully utilizes pre-trained data and enhances the language model’s ability to understand complex tasks through a task planning prompt method that combines code and annotations. Based on this, a new framework for large language model thinking prompts, named ReACoGPT, is proposed. The language model using ReACoGPT prompts can accurately call multiple plug-ins and provide logical task planning capabilities based on facts, so that, while maintaining the logic of task planning, the actual requirements data can also be accurately utilized. Experimental results show that compared with existing methods, ReACoGPT has achieved improvements in multiple indicators on the RestBench dataset, confirming that the ReACo prompt method can enhance the planning and reasoning capabilities of large language models, effectively utilize a large amount of training data to effectively plan tasks, and promote the further development of large language models in tool learning.
Reasoning to Annotation and Coding (ReACo) / tool invocation / chain-of-thought / large language model {{custom_keyword}} /
Table 1 Experimental result表 1 实验结果 |
| 方法 | TMDB | Spotify | ||||
|---|---|---|---|---|---|---|
| Success/% | Correct Path/% | ∆ Solution Len. | Success/% | Correct Path/% | ∆ Solution Len. | |
| Offline | 29 | 33 | +1.52 | 14.5 | 36.4 | +1.10 |
| ReAct | 44 | 57 | +0.76 | 54.5 | 49.1 | +0.31 |
| Reflexion | 52 | 59 | +1.37 | 59.6 | 61.4 | +1.68 |
| RestGPT | 75 | 79 | +0.55 | 72.7 | 74.5 | +0.25 |
| ReACoGPT | 81 | 86 | +0.52 | 73.6 | 78.9 | +0.40 |
| 加粗表示该项数值为列表中效果最佳。 |
Table 2 Ablation results表 2 消融实验结果 |
| 方法 | TMDB | Spotify | ||||
|---|---|---|---|---|---|---|
| Success/% | Correct Path/% | ∆ Solution Len. | Success/% | Correct Path/% | ∆ Solution Len. | |
| RestGPT | 75 | 79 | +0.55 | 72.7 | 74.5 | +0.25 |
| ReACoGPT | 81 | 86 | +0.52 | 73.6 | 78.9 | +0.40 |
| ReACoGPT去除工具召回模块 | 28 | 20 | +2.47 | 12.2 | 15.7 | +2.06 |
| ReACoGPT去除任务规划模块 | 42 | 50 | +0.85 | 31.6 | 36.8 | +1.21 |
| ReACoGPT去除工具执行模块 | 14 | 82 | +0.45 | 12.2 | 14.0 | +0.34 |
| 加粗表示该项数值为列表中效果最佳。 |
| 1 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 2 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 3 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 4 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 5 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 6 |
江志英, 李宇洋, 李佳桐, 等. 基于层次分析的长短记忆网络(AHP-LSTM)的食品安全网络舆情预警模型[J]. 北京化工大学学报(自然科学版), 2021, 48(6): 98-107.
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 7 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 8 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 9 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 10 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 11 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 12 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 13 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 14 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 15 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 16 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 17 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| 18 |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
| {{custom_ref.label}} |
{{custom_citation.content}}
{{custom_citation.annotation}}
|
PDF(1308 KB)
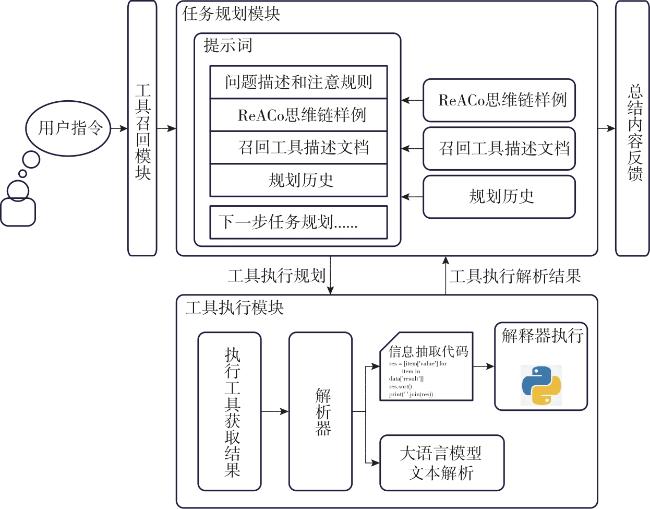
 Fig. 1 ReACo prompt compositionFig. 2 ReACoGPT architectureFig. 3 The components of the Planner prompt
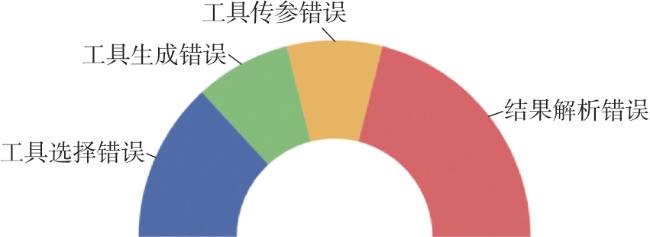
Fig. 1 ReACo prompt compositionFig. 2 ReACoGPT architectureFig. 3 The components of the Planner prompt Table 1 Experimental resultTable 2 Ablation resultsFig. 4 Distribution of different types of errors
Table 1 Experimental resultTable 2 Ablation resultsFig. 4 Distribution of different types of errors/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}