
引言
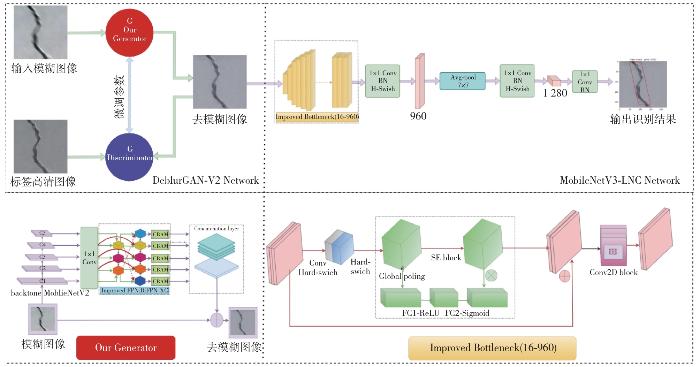
1 DeblurGAN与MobileNet网络
2 轻量化混凝土裂缝图像识别网络
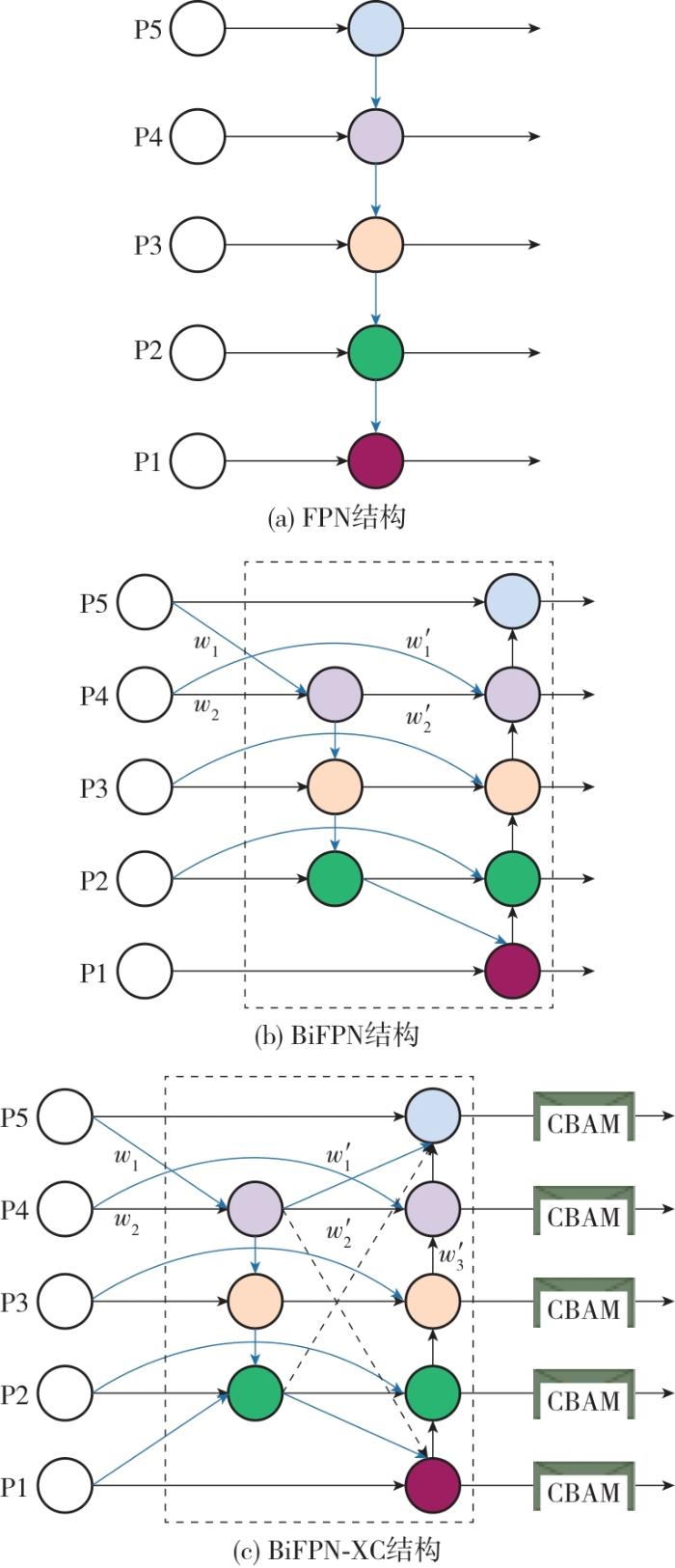
2.1 BiFPN⁃XC模块
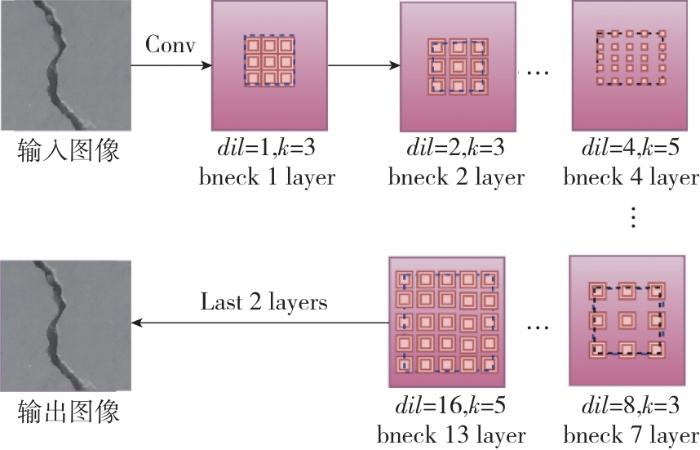
2.2 MobileNetV3⁃level network connection(LNC) Bottleneck模块
2.3 评价指标
3 实验与结果分析
3.1 数据集


3.2 实验环境与配置
3.3 结果与讨论
表1 不同注意力机制模块在二分类任务中的表现Table 1 Performance of different attentional mechanism modules in the dichotomous categorization task |
| 类别 | 网络模块 | F |
|---|---|---|
| 基础网络 | Resnet18 | 78.70 |
| 空间注意力机制 | +self⁃attention | 79.01 |
| +non⁃local | 79.22 | |
| 通道注意力机制 | +SE | 80.42 |
| +SK | 82.34 | |
| 混合注意力机制 | +CBAM | 81.79 |
| +DANet | 82.05 |
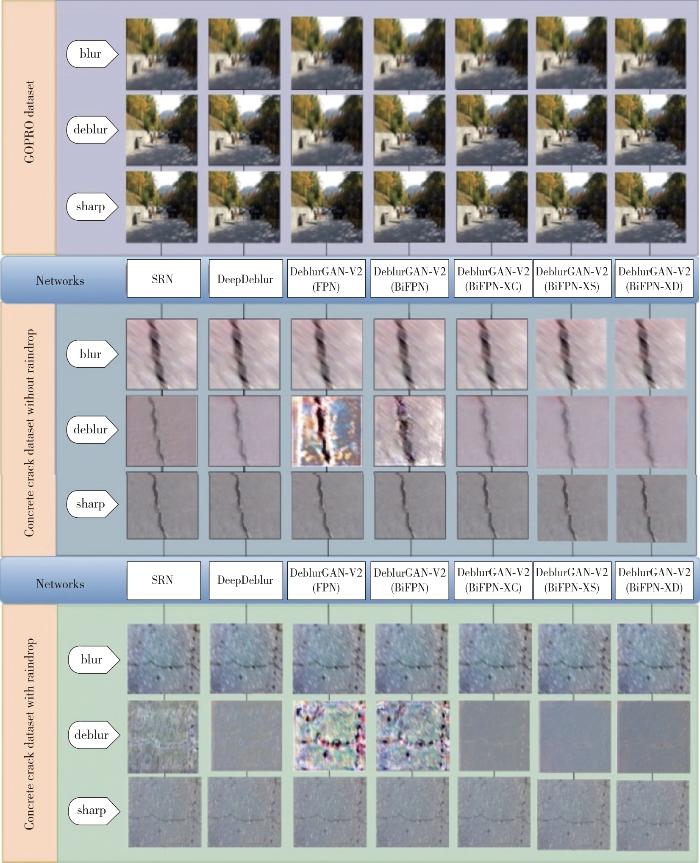
图6 不同网络在不同数据集的同一张图像上运动模糊复原前后与高清图像的对比Fig.6 Comparison of different networks on the same image on different datasets before and after motion blur recovery with HD images |
表2 GOPRO数据集上的运动模糊复原实验结果Table 2 Motion⁃blur recovery experiment results for the GOPRO dataset |
| 网络 | 金字塔结构 | PSNR | SSIM | 单张图片 处理时间/s |
|---|---|---|---|---|
| SRN[20] | - | 25.10 | 0.890 | 2.10 |
| DeepDeblur | - | 24.42 | 0.812 | 4.03 |
| DeblurGAN⁃V2 | FPN | 23.34 | 0.678 | 0.06 |
| DeblurGAN⁃V2 | BiFPN | 23.45 | 0.682 | 0.10 |
| DeblurGAN⁃V2 | BiFPN⁃XS | 23.54 | 0.693 | 1.58 |
| DeblurGAN⁃V2 | BiFPN⁃XC | 23.51 | 0.691 | 0.12 |
| DeblurGAN⁃V2 | BiFPN⁃XD | 23.47 | 0.687 | 1.02 |
表3 无雨天气混凝土图像运动模糊数据集上的运动模糊复原实验结果Table 3 Motion⁃blur recovery experiment results on a motion blur dataset of concrete images with no raindrop |
| 网络 | 金字塔结构 | PSNR | SSIM | 单张图片 处理时间/s |
|---|---|---|---|---|
| SRN[20] | - | 22.87 | 0.675 | 1.90 |
| DeepDeblur | - | 21.24 | 0.640 | 4.01 |
| DeblurGAN⁃V2 | FPN | 19.94 | 0.569 | 0.05 |
| DeblurGAN⁃V2 | BiFPN | 20.71 | 0.580 | 0.08 |
| DeblurGAN⁃V2 | BiFPN⁃XS | 21.03 | 0.631 | 1.46 |
| DeblurGAN⁃V2 | BiFPN⁃XC | 20.87 | 0.628 | 0.11 |
| DeblurGAN⁃V2 | BiFPN⁃XD | 20.79 | 0.624 | 0.97 |
表4 模拟雨水天气混凝土图像运动模糊数据集上的运动模糊复原实验结果Table 4 Motion⁃blur recovery experiment results on a motion blur dataset of concrete images with simulated raindrop |
| 网络 | 金字塔结构 | PSNR | SSIM | 单张图片 处理时间/s |
|---|---|---|---|---|
| SRN[20] | - | 23.21 | 0.693 | 2.31 |
| DeepDeblur | - | 22.81 | 0.672 | 3.97 |
| DeblurGAN⁃V2 | FPN | 20.94 | 0.571 | 0.07 |
| DeblurGAN⁃V2 | BiFPN | 21.71 | 0.581 | 0.10 |
| DeblurGAN⁃V2 | BiFPN⁃XS | 22.02 | 0.629 | 1.59 |
| DeblurGAN⁃V2 | BiFPN⁃XC | 21.95 | 0.633 | 0.11 |
| DeblurGAN⁃V2 | BiFPN⁃XD | 21.91 | 0.630 | 1.21 |
表5 不同网络在混合天气的混凝土图像运动模糊数据集上的裂缝图像识别实验结果Table 5 Experiment crack image recognition by different networks for the mixed weather concrete image motion blur dataset |
| 网络 | P | R | F | 单张图片处理时间/s | |
|---|---|---|---|---|---|
| 单模型 | MobileNetV3 | 0.603 | 0.625 | 0.614 | 0.40 |
| MobileNetV3⁃LNC | 0.641 | 0.634 | 0.637 | 0.38 | |
| ShuffleNetV2[21] | 0.468 | 0.493 | 0.480 | 0.32 | |
| EfficientNetV2[22] | 0.745 | 0.525 | 0.616 | 0.87 | |
| 双模型 | MobileNetV3(DeblurGAN⁃V2) | 0.855 | 0.884 | 0.850 | 0.51 |
| MobileNetV3⁃LNC(DeblurGAN⁃V2) | 0.889 | 0.912 | 0.900 | 0.47 | |
| ShuffleNetV2(DeblurGAN⁃V2) | 0.715 | 0.772 | 0.742 | 0.49 | |
| EfficientNetV2(DeblurGAN⁃V2) | 0.901 | 0.897 | 0.899 | 1.17 | |
| - | 维纳滤波⁃SVM[5] | 0.763 | 0.825 | 0.793 | 1.97 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
表6 双模型网络在混凝土图像运动模糊数据集上的消融实验结果Table 6 Dual model network ablation experiment results for the concrete image motion blur dataset |
| 运动模糊复原网络 | 裂缝识别网络 | P | R | F | 单张图片处理时间/s |
|---|---|---|---|---|---|
| DeblurGAN⁃V2(FPN) | MobileNetV3 | 0.816 | 0.824 | 0.820 | 0.42 |
| DeblurGAN⁃V2(BiFPN) | MobileNetV3 | 0.848 | 0.869 | 0.858 | 0.45 |
| DeblurGAN⁃V2(BiFPN⁃XC) | MobileNetV3 | 0.889 | 0.912 | 0.900 | 0.47 |
| DeblurGAN⁃V2(FPN) | MobileNetV3⁃LNC | 0.838 | 0.836 | 0.837 | 0.39 |